Font View¶
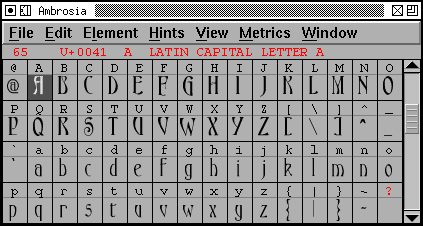
The font view is a list of all the glyphs available in the given font.
You may chose to display it at various sizes, by default it will be displayed with the outline font rasterized on a 24 pixel em square. You may display it at 36, 48, 72 and 96 pixel sizes as well. You may also choose to look at an anti-aliased greymap (the above image is anti-aliased). These are slower to generate but look nicer (Comparison).
If you have an encoding slot which has nothing in it (as opposed to an encoding which maps to a space glyph) then that will be shown by a faint red X drawn across the box.
Above each image of the glyphs in the font is a label indicating the glyph in some conventional format. Usually this is just a small image of the glyph in a standard font (as it is above), but you can change it to show the glyph’s name, unicode code point or encoding (in hex). In small views (24 pixel view for instance) there may not be room for the entire label, and it will appear truncated.
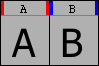
If a glyph has been changed since it was last hinted (PostScript), or if a glyph contains contours but has no instructions (TrueType), then its label will be edged with blue bars. If the glyph has out of date instructions (TrueType), then its label will be edged with red.
If one of your glyphs has something in its background layer then this will be indicated visually (currently by darkening the background of the glyph label).
Normally the view will display the foreground layer of the font, but you may change it to display any layer (other than the background layer) with View->Layers->?
You may also display any of the bitmap fonts you have generated from the outline glyphs. Simply go to the View menu and select the one you want.
If you look at a bitmap version of the font, and it does not contain a glyph for which there is an outline glyph (ie. the font needs its bitmaps regenerated) then the missing glyph will be outlined in red to bring it to your attention more easily.
Small bitmap fonts will be magnified. If the pixelsize of the font is less than 10 it will be shown 3 times normal size, if less than 20 twice normal size.
Underneath the menu bar is some information on the last glyph selected. First is the encoding of the glyph in the current font expressed in decimal. Next is the unicode code point for the glyph (or ???? if it is not a unicode character). Next the postscript name for the glyph, and finally the unicode name. Not all unicode characters will have unicode names (the CJK characters do not for example)
If you move the cursor to a glyph and let it rest there a small popup window will appear containing information about that glyph. If you depress the control key then this window is locked in place until you move the mouse.
You may display metrics lines (baseline, origin and advance width) in the font view. (View -> Show H Metrics). If you do so, I suggest viewing the font at a large pixel size, otherwise the window looks too confusing.
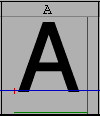
A 96 pixel display showing the various horizontal metric lines.
The blue line is the baseline
The small red tick on the left marks the glyph origin.
The green line on the right shows where the advance width is while the bottom green line shows how long it is. (normally you will not display both at once)
The glyph is centered horizontally, and the font ascent is the top of the box displaying it, while the descent is the bottom.
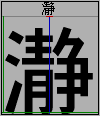
A 96 pixel display showing the various vertical metric lines.
The blue line down the center is the vertical baseline.
The red bar at the top (over writing the ascent line) is the vertical origin.
The green line at the bottom shows where the vertical advance is while the green line on the right shows how long it is. (normally you will not display both at once)
You may select any number of glyphs in the font by dragging through them. You may use shift-click to select (or deselect) additional glyphs. You may also use the arrow keys to move around (and shift-arrow to select). To some extent the order you select glyphs in will be remembered and a few commands will make use of that.
You may drag and drop selected glyphs into
- The metrics view
Where they will be inserted into the display before the selected glyph (selected in the metrics view) in the order in which you selected them in the font view.
- The outline view
Where they will appear as references
- The glyph info substitutions/ligature dlg
Where they will appear as a substitution or ligature.
The [Tab] key will move to the next glyph with something in it, and Shift-[Tab] will move to the previous glyph with something interesting.
You can perform various operations on the selected glyphs:
Apply a general transformation (ie. move 20 units right and then rotate 180°)
Expand all paths to be stroked paths
Clean up areas where several paths intersect
Simplify paths
Build Accented Characters
Regenerate bitmaps
Autohint
Control various metrics settings
And, of course, you can cut and paste. Normally copying a glyph will copy that glyph and any bitmaps associated with it, but you can use the Edit->Copy From menu item to change this so that only entries from the currently displayed font are copied. So if a 12 pixel font is being displayed then only the bitmaps from the 12 pixel bitmap font will be copied in this mode. Cut and Clear will clear those things which would be copied.
Paste is a little more complicated. In general it will paste whatever is in the clipboard, regardless of the copy mode. So if the clipboard contains a 12pixel bitmap and the font view is displaying outlines, then pasting it will paste it into the 12pixel font none the less. There is one exception to this. If the clipboard contains a 12 pixel bitmap and the font view is currently display a 17pixel bitmap then the paste will go into the displayed bitmap.
A Paste from the font view will delete whatever splines were in the glyph beforehand (while a paste in the outline glyph view will merge the new set of splines with the old). Paste from the font view will also set the width of the glyph.
You can scroll the display to any particular character by typing that character. There is also a dialog which allows a slightly more general way of jumping around. You may type in the glyph’s name (all glyphs in a font will be named), its encoding value, its unicode encoding value, or (for 2 byte fonts) its ku ten specification.
Pressing the right mouse button invokes a popup menu.
Encodings and Character Sets¶
A Character Set is a set of characters (for example all the letters of the alphabet would be one character set). An encoding is a function that takes a number (often between 0 and 255) and maps it to a character. Often these two are used synonymously as an encoding generally implies a given character set. (strictly speaking a character set is an unordered collection with no implied encoding, and some encodings work with multiple character sets).
All fonts in fontforge have both a character set and an encoding. The character set is just the set of characters in the font. The encoding is the way those characters are ordered (or sometimes, the way the first 256 are ordered). The font info dialog allows you to chose the encoding (and character set) you wish for a font. Often a font will have a few extra glyphs that don’t fit into the character set specified by the encoding, these glyphs will be placed at the end of the font and when the font is output (ie. postscript is generated, or a bitmap font created) the glyphs will be included in the font but they will not be encoded (this can be useful, especially in postscript where it is possible to reencode a font at run time. Thus a font might have all the glyphs needed both for a cyrillic character set and for a latin one, but only one character set at a time would be encoded).
It is possible for an encoding not to be one-to-one. That is there may be several characters that might lead to the same underlying glyph (the classic example is the non-breaking space which often uses the same glyph as the breaking space). When FontForge encounters such an encoding it will create a character structure for each entry, one of those structures will contain the data for drawing the glyph, the other(s) will contain a reference to the one real character. All characters will have the same name. When FontForge generates a font it looks for this case and turns it into a font whose encoding vector contains multiple references to a glyph.
It is also possible to have an encoding where a single character can lead to several different glyphs depending on the context. In arabic, for example, most characters have at least four different glyphs depending on whether the character is found initially, medially or finally in a word, or if it appears by itself (isolated).
You may also create a custom encoding. (Generally, only the first 256 entries of a Custom encodings will actually be part of a font’s encoding vector). You may change the name of any glyph in the font with the Element->Char Info command. This will force the font to have a custom encoding.
There are many standard encodings built in to the program. There are 14 ISO 8859 encodings, the encoding used by the Macintosh for the US and Western Europe, the encoding used by MS Windows for the US and Europe (which is a slight extension of ISO 8859-1). There are also several 2-byte encodings built in. Several of these are subsets of unicode (whose goal is to specify every character currently used by humans). There are many large CJK (Chinese, Japanese, Korean) two byte encodings. You can also add your own encodings with the Encoding menu. A brief description of what’s in the encodings also appears on that page.
There may be some slight differences between one vendor’s definition of an encoding and another. I try to follow those encodings specified by the Unicode consortium. I notice that the Symbol encoding used by Microsoft differs from the Unicode one (usually just be substituting synonyms, Omega for Ohm sign for instance).
Adobe did not choose their naming conventions very well for Greek letters. They assigned the name “mu” to Micro Sign, “Delta” to Increment and “Omega” to Ohm Sign. So the Greek alphabet has ugly nameless holes in it.
CID fonts (see below) have no encodings. Instead they are designed to be associated with one or several cmap files which provide encodings in a general way. cmap files are beyond the scope of FontForge. Adobe has defined many which are freely available.
There is one final encoding called “Glyph Order”. This encoding is just the glyphs in the order in which they were read from the original font.
Unicode (ISO 10646)¶
PostScript® assigns a name to every unicode character. Some of these names are fairly obvious like “A” for the first letter of the latin alphabet, others are more obscure like “afii57664” for hebrew alef, while others are just “uni8765” for the unicode character at 0x8765.
PostScript Unicode encoding does not quite mesh with the unicode standard. This is probably because PostScript deals in glyphs and Unicode deals with characters so PostScript sees no distinction between space and nobreak space (and so does not encode the latter) while Unicode does.
According to the unicode website the first 256 character positions of unicode and ISO 8859-1 (ISO Latin1) are the same. However the PostScript encoding of ISOLatin1 is slightly different from that specified for unicode. I cannot explain the reasoning behind this. FontForge does not use PostScript’s ISOLatin1 Encoding vector, instead it uses the first 256 code positions of the unicode encoding vector (slightly modified by me to conform to Unicode conventions rather than PostScript. So I include nobreak space and the soft-hyphen).
FontForge supports two slightly different unicode encodings. The first contains only the first 65536 characters of unicode (those in the Basic Multilingual Plane, or BMP), while the second can contain as many characters as you have memory for. Character definitions are still sparse outside of the BMP so at the moment you probably want to use just the BMP. Currently there are only definitions for plane 0 (BMP, U+0000-U+ffff), Plane 1 (SMP, Secondary Multilingual Plane, U+10000-U+1ffff), Plane 2 (SIP, Supplementary Ideographic Plane, U+20000-U+2ffff), and Plane 14 (SSP Supplementary Special-purpose Plane, U+e0000-U+effff).
CID keyed fonts¶
The standard mechanisms that postscript provides work reasonably well for alphabets and syllabaries, but the massive number of characters needed for CJK (Chinese, Japanese or Korean) fonts require more complex machinations. Adobe’s current solution is the CID-keyed font, a font consisting of several subfonts each a collection of glyph descriptions with no encoding imposed on them and no names given to them.
If FontForge loads in a CID keyed font it will enable a special menu called CID which (among other things) displays the list of all the sub-fonts in the font. When it starts up FontForge will pick (practically at random) a sub-font to display in the font view. You may change which font is displayed by the CID menu.
The CID menu also allows you to turn a normal font into a CID keyed font. It creates a collection containing just the original font (you may add other fonts, or blank fonts, later). But before it can create a collection FontForge needs to know what glyph set you will be using. A glyph set is just a collection of glyphs, and you may define your own if you wish (but if you do you have to define your own cmap files, etc and it’s probably not worth it). Adobe has defined glyph sets for Japanese (actually there are two, one corresponding to JIS208 and one to JIS212), Korean (Wansung & Johab), Traditional Chinese (Big5) and Simplified Chinese (GB2312). Although these glyph sets are based on the standards mentioned, they each have many additional glyphs. Adobe also defines a glyph set that works for Unicode, but it is called “Identity” instead. FontForge does not have these glyph sets built in to it, each must be loaded the first time it is used. I provide one file for each of the above glyph sets, they have an extension of “.cidmap”, and you may download them all from here.
(There are also many other character sets floating around feel free to install them yourself).
Adobe identifies each glyph set by a three values: a registry, an ordering and a supplement. The registry is the name of the organization that is defining the glyph set (Adobe calls itself Adobe), an ordering identifies the glyph set (Japan1, Korea1, etc.) and the supplement indicates how many times the ordering has been revised. Glyphs may only be added to an ordering, never removed, so an old font will be perfectly described by a newer glyph set, while a new font described by an old glyph set will have some unavailable glyphs. So a full cidmap name will look like:
Adobe-Japan1-4.cidmap
Adobe-Korea1-2.cidmap
Warning
FontForge’s support for CID-keyed fonts is rudimentary; especially attempting to use Compact encodings and the Metrics View in CID-keyed fonts is known to cause issues and crashes. At one time, the memory usage of CID-keyed fonts was seen as very worrisome (≈250MB), however as even most modern smartphones can support such usage it is no longer a concern for the majority of users. Therefore, we recommend that if you will make serious edits to a CID-keyed font, you flatten it first to prevent crashes and memory corruption. Bug fixes are always welcome-to start, see issue №3946.
The Remove Undoes command will allow you to free up memory if you think you may be running short. FontForge is not always able to protect itself against running out of memory, sometimes the OS just sends it a SIGKILL signal.
Multiple Master Fonts¶
If the font is a Multiple Master Font there will again be several subfonts only this time all the subfonts contain the same glyph set. Each subfont provides glyphs for one style of the font family. The MM menu allows you to control which style of the family is visible in the font view, and provides a few other commands for manipulating multiple masters.
Vertical Metrics¶
CJK fonts generally should have vertical metrics. Latin (Cyrillic, Greek) fonts generally should not. If FontForge reads in a font with vertical metrics it will retain those metrics, but when FontForge creates a new font then that font will not have vertical metrics enabled.
To enable vertical metrics for a font go to
Element->Font Info and select the General tab and
check the [*] Has Vertical Metrics checkbox. This will allow you to set the
vertical origin for the font and it will give every glyph a default vertical
advance of the emsize of the font (ascent+descent).
The vertical origin is the y height (in the design coordinate system) of the origin for vertical metrics.
In the outline glyph view you will be able to adjust the vertical metrics just as you adjust the horizontal metrics.
You can view the vertical metrics in the font view just as you can the horizontal metrics with View->Show V Metrics.